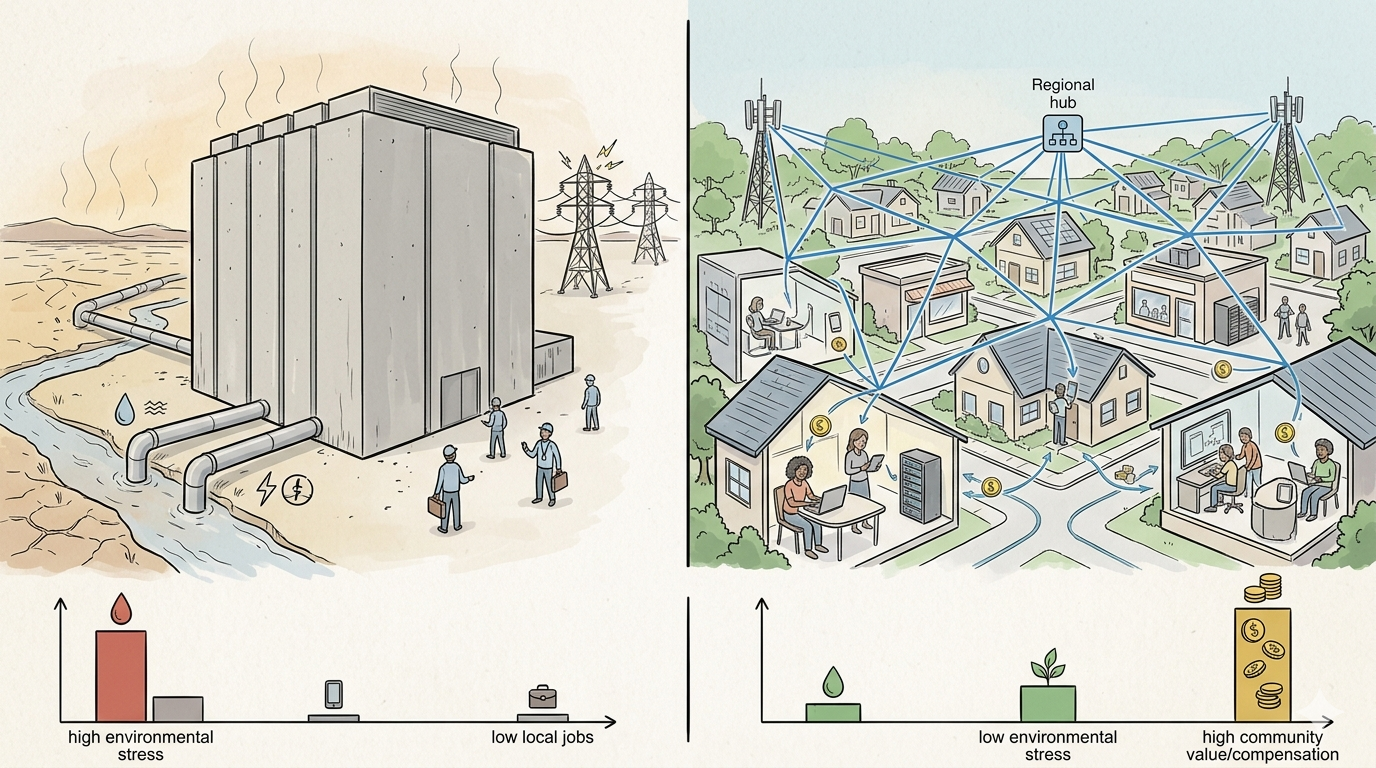

The Data Center Debate Isn’t Binary
In Goodyear, Arizona, a suburb west of Phoenix, residents have spent the last two years watching data centers multiply along the I-10 corridor. The facilities are enormous — windowless, humming structures that consume water and power at a scale that strains comprehension. Local officials approved them with the promise of jobs and tax revenue. The construction crews came and went. The permanent workforces never materialized at the scale implied. What remained were the facilities themselves — drawing on the same aquifers the community depends on, consuming power that pushes the regional grid during summer heat events, and generating a fraction of the lasting economic activity the approvals were sold on. Goodyear is not exceptional. It is representative.
On March 25, 2026, Senators Bernie Sanders and Edward Markey, along with Representative Alexandria Ocasio-Cortez, introduced legislation to impose a moratorium on the construction of new data centers in the United States. The bill was met, predictably, with alarm from the technology industry and dismissal from those who view any constraint on AI development as economically reckless. It was met, equally predictably, with enthusiasm from environmental advocates who have watched data center construction accelerate across American communities with consequences that are difficult to ignore.
Those consequences are not abstractions. A single modern AI data center consumes as much electricity as 100,000 average American households. The largest facilities currently under development will consume twenty times more 1. In 2025, North American data centers drew nearly one trillion liters of water for cooling2 — water pulled from the same rivers, aquifers, and municipal systems that the surrounding communities depend on. In the Phoenix metropolitan area alone, data centers consume an estimated 385 million gallons of water annually3. These are not the externalities of a mature, stable industry absorbing the costs of its own growth. They are the externalities of an industry expanding at a pace that local infrastructure, local water supplies, and local communities were not designed to absorb.
The frustration animating the Sanders-Markey-Ocasio-Cortez bill is legitimate. The communities bearing these costs did not choose to host the infrastructure of the AI economy. They did not negotiate the terms. They were not meaningfully compensated. And in most cases, the economic benefits the industry promised — jobs, tax revenue, local investment — have arrived in forms far narrower than advertised. The permanent workforce of a modern hyperscale data center is remarkably small relative to its physical and environmental footprint. The construction jobs are temporary. The tax arrangements are frequently the result of incentives that reduce rather than increase the public benefit.
But the moratorium debate, as it is currently being conducted, rests on an assumption that has not been examined: that centralized data centers are the only architecture capable of delivering the compute that AI requires. That assumption is not a technical fact. It is not an engineering constraint. It is an architectural habit — one the industry has a powerful financial interest in preserving, and one that the policy conversation has not yet thought to question.
The question worth asking is not only whether we should build fewer data centers. It is whether we need to build them at all.
The moratorium debate has settled into a familiar shape. On one side, the technology industry argues that data centers are the unavoidable infrastructure of economic competitiveness — that any constraint on their construction is a constraint on American innovation. On the other, a growing coalition of environmental advocates, community organizations, and now members of Congress argues that the costs being imposed on communities and ecosystems are no longer acceptable. Both sides are arguing, with considerable energy, about how much of the same thing to build.
Neither side has much incentive to ask whether the thing itself is necessary.
The technology industry has spent decades and hundreds of billions of dollars building centralized infrastructure. Questioning its necessity is not a conversation its incumbents are structured to have. The moratorium advocates need the threat to remain total — a partial threat produces partial urgency. And the policy apparatus that mediates between them operates almost entirely without technical staff who understand what the current architecture of the internet already makes possible.
The result is a debate conducted in good faith about the wrong question. The right question is not how many data centers to build. It is whether the compute the AI economy requires can be delivered in a fundamentally different way — one that distributes the infrastructure, distributes the cost, and distributes the benefit. The answer, as the last two decades of computing history make clear, is yes. The policy conversation simply hasn't looked there yet.
The Architecture Already Exists. The Policy Conversation Just Hasn't Found It Yet.
In 1999, researchers at UC Berkeley launched SETI@home. The premise was straightforward and, at the time, quietly radical: rather than building a supercomputer to analyze radio telescope data, they would use computers that already existed — in homes, offices, and university labs — donating their idle processing cycles to a shared scientific purpose. Over two decades, more than 5.2 million participants contributed their hardware to a production-grade scientific computing network that delivered results no centralized facility could have matched at comparable cost4. The model worked. It worked at scale. And it worked on consumer-grade residential hardware.
SETI@home was not an anomaly. It was a proof of concept that the research community immediately recognized and extended. Folding@home, launched out of Stanford University, applied the same architecture to simulating the molecular behavior underlying diseases including Alzheimer's, cancer, and Parkinson's. When COVID-19 struck in 2020, hundreds of thousands of volunteers activated their home computers and gaming rigs. The result was historically unprecedented: Folding@home became the first computing system to break the exascale barrier, reaching a peer-reviewed peak performance of 1.01 exaFLOPS — more raw compute power than the world's most powerful supercomputers at the time — achieved entirely through the aggregated processing of volunteer residential and institutional hardware5. It did not require a single new data center.
To understand the scale at stake, consider a rough order of magnitude. The United States has approximately 330 million smartphones, 270 million personal computers, and tens of millions of additional connected devices in homes and small businesses — the overwhelming majority sitting idle for 16 or more hours each day, 92% of which are connected by a broadband internet connection6. Folding@home, at its COVID-19 peak, aggregated roughly 4.8 million CPU cores and 280,000 GPUs from volunteer devices to achieve exascale performance. The installed base of idle consumer hardware in the United States is orders of magnitude larger. The compute is not missing nor disconnected. It is simply unorganized, uncompensated, and invisible to the policy conversation debating whether to build more of what we already have in abundance.
The workloads most suited to this architecture are not frontier model training — which genuinely requires specialized hardware at scale — but inference, content delivery, and edge processing: the tasks that account for the vast majority of data center capacity currently being built and the environmental costs being debated.
These are not consumer experiments. They are peer-reviewed, formally documented scientific computing networks that vindicated a fundamental architectural principle: computation distributed across geographically dispersed hardware, coordinated by a central orchestration layer, can outperform centralized infrastructure at a fraction of the cost.
The commercial world has reached the same conclusion, though not yet at the residential layer. The internet's largest delivery platforms — Cloudflare, Akamai, Fastly — are all built on the premise that compute should happen closer to where it is needed. Their networks span hundreds of cities, distributing workloads regionally rather than serving the entire country from a handful of mega-facilities. The direction is unambiguous: the industry has been moving away from centralization for two decades. What those platforms have not yet done is extend that logic to its natural conclusion — past the regional data center and into the neighborhoods, homes, and small businesses where the hardware already exists and sits largely idle.
A new category of participant-owned infrastructure has emerged to test exactly this model commercially — networks that aggregate hardware in homes and businesses, coordinating idle capacity to serve real workloads outside of traditional data center facilities. The concept has attracted substantial capital: the sector raised over $1 billion in private investment in 2025 alone and has deployed tens of millions of active devices globally7.
The category has not been without problems. Some networks in this space built their economic models on cryptocurrency tokens rather than straightforward cash compensation — and when token values collapsed, so did participant incentives, network coverage, and in some cases, the underlying business.8 These failures are real, and the skepticism they generated is earned.
But the failure of a token-based incentive model does not invalidate the underlying architectural principle — any more than the failure of early dot-com companies invalidated the internet. The token-based incentive structure was not inherent to the architecture. It was a design choice. And design choices can be changed. The more fundamental question for policymakers is not which specific network gets there first, but whether the architectural model — community-owned, residentially-distributed compute, compensated in straightforward cash rather than speculation — is viable. The scientific computing precedent suggests it is. The economic logic suggests it should be. Whether it can be delivered at commercial scale is the infrastructure challenge this moment demands.
That distinction — between community-owned infrastructure built on transparent cash economics and the speculative token networks that preceded it — is precisely the one the policy conversation has not yet made. It matters, because the model that serves the public interest is not the one that collapsed. It's the one being built on its lessons.
Meanwhile, at the device level, the architecture has moved further still. IBM's own technical documentation defines edge computing for IoT as "the practice of processing and analyzing data closer to the devices that collect it rather than transporting it to a data center first."9 The company projects that 75% of enterprise data will be processed at the edge — compared to only 10% previously10. In manufacturing, retail, healthcare, and transportation, STL Partners' 2025 research describes the edge computing market as having reached a "tipping point" for how industry stakeholders think about deployment, AI workloads, and infrastructure models. The shift is not emerging. It has already arrived.
The pattern is consistent across every layer of the stack — from volunteer scientific computing to commercial delivery networks to IoT device architecture: the industry has been systematically discovering that distributing compute closer to where it is needed produces better outcomes at lower cost, with less environmental concentration. The question the current policy debate has not yet asked is the obvious one: if compute can be distributed to 330 cities, to thousands of network hotspots, to the factory floor and the retail shelf — why are we still building it as if the only option is a new facility consuming the water supply of a mid-sized American city?
The distributed computing model is not a future possibility. It is a present reality operating across multiple industries and infrastructure categories simultaneously. The data center debate has simply not looked there yet.
There is a standard story told about data centers and the communities that host them. The story goes like this: a technology company selects a site, negotiates with local officials, breaks ground on a facility that will power the digital economy, and in return delivers jobs, tax revenue, and economic vitality to a community that might otherwise be struggling to attract investment. It is a story the industry tells fluently, and it is a story that local and state officials have been eager to believe.
The evidence, accumulated now across hundreds of communities and dozens of independent analyses, tells a different story.
The jobs are real — but they are not what was advertised. A large-scale data center creates between 1,000 and 1,500 construction positions during the build phase — well-paying work for electricians, ironworkers, and building trades that typically lasts 18 to 24 months before it ends. The permanent operational workforce that follows is, by any honest accounting, remarkably small: typically between 50 and 200 full-time employees for a facility consuming as much power as a small city. Brookings Institution analysis describes the standard data center development model as one that delivers "short-term construction jobs and revenue, but little durable local economic upside."11 A January 2026 report from Food & Water Watch found Microsoft announcing $3.3 billion in data center investment paired with 800 permanent jobs — while simultaneously cutting 7,500 positions elsewhere12. NPR's reporting on data center expansion found the same pattern repeated across the country: record-setting price tags, communities wooed with promises, and permanent workforces that never materialized at the scale implied1314. Good Jobs First concluded that data centers "can replace as many jobs as they create" when accounting for the energy and infrastructure they consume that might otherwise support more labor-intensive industries 15.
For the family living two miles from a hyperscale facility, the distinction between 1,500 construction jobs that lasted eighteen months and a permanent workforce of 200 is not a policy abstraction. It is the difference between a promise kept and a promise broken.
The tax revenue story is similarly complicated. At least 36 states now offer targeted tax incentives for data center development — exemptions, credits, and abatements designed to attract facilities to their jurisdictions. Good Jobs First examined these programs and found that of the 32 states offering tax incentives, 12 don't even disclose the aggregate revenue losses the programs produce. CNBC reported in June 2025 that states are forfeiting hundreds of millions of dollars in tax revenue to technology companies — with one state's own analysis classifying its data center exemption as a "moderate economic benefit" that "does not pay for itself."16 Indiana's Citizens Action Coalition estimated the state's sales tax exemption could cost tens of billions of dollars over 50 years — and noted the state had never produced an estimate of the figure.17 "We know of no other form of state spending that is so out of control," Good Jobs First wrote. States are, in other words, competing to subsidize some of the most profitable corporations on earth in exchange for facilities that consume their water, strain their grids, and employ a fraction of the workforce the investment implied.
The communities that bear the costs most directly are not the ones negotiating the terms. The Lincoln Institute of Land Policy has documented how communities across the United States are wooing data centers with tax breaks and incentives while being entirely unprepared for the demands those facilities place on land, water, and power infrastructure18. In Texas, where the data center boom has concentrated with particular intensity, AI data centers are consuming 49 billion gallons of water19 while residents in drought-affected areas are asked to cut back on showers. Approximately 1,260 data centers in the United States are located in or adjacent to disadvantaged communities — communities that absorb the environmental footprint while the economic benefits flow primarily to corporate balance sheets and their shareholders20.
This is not an argument against economic development. It is an argument about what economic development actually looks like when the infrastructure model is examined honestly. The relevant comparison is not between data centers and nothing. It is between a model that concentrates infrastructure ownership in a small number of corporate hands — extracting value from communities while offering them temporary construction work and opaque tax arrangements — and a model that distributes both the infrastructure and the economic return to the people who host it.
The rooftop solar analogy is instructive here. For decades, energy generation in the United States operated on the same centralized logic as data centers: large utilities owned the generation infrastructure, ratepayers consumed the output, and the economic benefit of the asset flowed to the corporation. Distributed solar changed that logic. When households and small businesses became energy producers — contributing power back to the grid and receiving compensation for what they generated — the economic relationship between infrastructure and community was fundamentally restructured. 21 The hardware investment was made by individuals. The return flowed to individuals. The grid became more resilient because the generation was distributed. The Department of Energy's research on distributed solar documents this dynamic directly: distributed generation reduces the infrastructure investments utilities must make while simultaneously building community wealth. The infrastructure cost is already sunk. The resource — sunlight, idle processing capacity — is underutilized. And the economic upside, which has historically flowed to centralized operators, can instead flow to individuals.
The data center debate has not yet asked whether the same restructuring is possible for compute. It should.
The moratorium debate, as it currently stands, is asking one question: how many new data centers should be built. That is a reasonable question. It is not the right question — or at least not the complete one. The more consequential questions have not yet entered the policy conversation, and they will not unless policymakers, advocates, and the public begin demanding they be asked.
The first question is one of transparency. Congress has already recognized that the data center industry operates with a remarkable degree of opacity about its own impact. The Data Center Transparency Act22, introduced in December 2025, would require the EPA to report on data centers' effects on air quality, water consumption, and pollution discharge — and require the Energy Information Administration to collect and publish electricity consumption data for every data center in the United States. Senator Dick Durbin's companion Data Center Water and Energy Transparency Act23, introduced March 25, 2026, goes further: requiring data center operators to disclose both current and projected energy and water consumption to the states where they operate. These bills have not yet passed. They should. A policy debate about an industry whose environmental footprint is not publicly tracked in any systematic way is a debate conducted without its most basic inputs. Before Congress can responsibly evaluate a moratorium, it needs the data the moratorium's proponents are rightly demanding be made visible.
The second question is one of alternatives assessment. The legislative and regulatory apparatus that evaluates infrastructure development in the United States is well designed to ask: should this facility be built, and under what conditions? It is almost entirely unprepared to ask: does this facility need to exist in this form? Environmental impact assessments for data centers focus on the project as proposed — the footprint, the water draw, the grid connection — not on whether the compute capacity the project provides could be delivered through a different architectural model. That gap is not a technical limitation. It is a policy choice. Requiring that major data center projects include a distributed alternatives assessment — a structured analysis of whether the compute capacity could be delivered through distributed or edge architectures — would not block development. It would ensure that the approval of centralized infrastructure reflects an informed decision, not a default.
The third question is one of ownership. Across the United States, communities are being asked to host compute infrastructure they do not own, do not control, and from which they derive limited lasting benefit. The policy imagination here has barely begun to develop. In 2025, a feasibility study commissioned for Louisville, Kentucky proposed what it described as America's first large-scale community-owned edge computing infrastructure: the Louisville Community Data Center Cooperative, a distributed mesh network of 5,000 computing nodes deployed across Louisville Metro, owned and governed cooperatively by the community it serves24. The proposal is notable not as a curiosity but as evidence that the policy and organizational frameworks for community-owned compute infrastructure are being actively developed — and that the question of who owns the infrastructure that powers the digital economy is one that communities are beginning to ask themselves. Federal and state incentive structures that currently flow almost exclusively to corporate data center operators could, with deliberate policy design, support community-owned distributed infrastructure instead. The fiscal tools exist. The policy will to redirect them does not yet.
These are not radical proposals. They are the natural extension of the same values that animate the moratorium debate itself — that the public interest should shape how compute infrastructure is built, where it is sited, who bears its costs, and who captures its benefits. A moratorium conducted without these questions on the table is an incomplete response to a legitimate problem. A policy conversation that incorporates them is one that might actually produce something durable.
There is a version of this story that ends with a moratorium — with Congress drawing a line around the data center model that has extracted water, strained grids, and made hollow promises to communities across the country. That outcome would be understandable. The frustration that produced it is legitimate.
But a moratorium is a pause, not a solution. And the more urgent work is not stopping something. It is building something different — infrastructure that is distributed by design, owned by the communities it serves, and compensated in the plain economic language of dollars rather than promises.
The policy imagination this moment requires is not central planning. It is the opposite: creating the conditions under which distributed innovation can happen at scale — in garages, in home offices, in the small businesses that line the main streets of every community currently being asked to host a hyperscale facility instead. The history of American infrastructure is, at its best, a history of distributed ownership: rural electric cooperatives, community banks, rooftop solar. The compute infrastructure of the AI economy does not have to be an exception to that history. It can be its next chapter.
The compute the AI economy requires does not need to come from the next facility built over someone's aquifer. The hardware to deliver it already exists in the neighborhoods that have been asked to absorb the costs of an infrastructure model they never chose and do not own. The architecture to coordinate it is proven. The economic logic to sustain it is sound.
What remains is the policy imagination to see it.
John Federico is a strategist and entrepreneur who has spent 30 years translating emerging technologies into practical products. He runs IT infrastructure systems at home at meaningful scale and is the founder of Evolving Edge, a distributed edge computing company.
This piece was researched and written with AI assistance. All arguments, editorial decisions, and factual verifications are the author's own.
- Energy and AI Report, International Energy Association, April 2025 ↩︎
- North America Data Center Water Consumption Market Size & Share Analysis - Growth Trends and Forecast (2025 - 2030), Mordor Intelligence ↩︎
- Drained by Data: The Cumulative Impact of Data Centers on Regional Water Stress, Ceres, September 2025 ↩︎
- SETI@home: An Experiment in Public-Resource Computing, November 2022 ↩︎
- SARS-CoV-2 simulations go exascale to predict dramatic spike opening and cryptic pockets across the proteome, Nature Chemistry, May 2021 ↩︎
- Ninety-two percent of US households now have broadband at home, Parks Associates, 2024 ↩︎
- State of DePIN 2025, Messari, January 2025 ↩︎
- The Cost of Building a DePIN Without a Clear Exit Liquidity Plan, Prasad Kumkar, Chainscore Labs ↩︎
- Edge Computing for IoT, IBM ↩︎
- Edge Computing Solutions, IBM ↩︎
- Turning the data center boom into long-term, local prosperity, February 2026 ↩︎
- The Urgent Case Against Data Centers, Food and Water Watch, March 2026 ↩︎
- What $10 billion in data centers actually gets you, April 2025 ↩︎
- Data centers bring money to small towns. But do they also bring jobs?, April 2025 ↩︎
- Cloudy Data, Costly Deals: How Poorly States Disclose Data Center Subsidies, Good Jobs First ↩︎
- In race to attract data centers, states can forfeit hundreds of millions of dollars in tax revenue to tech companies ↩︎
- The Hidden Costs of Data Centers, Citizens Action Coalition, January 2024 ↩︎
- Data Drain: The Land and Water Impacts of the AI Boom, October 2025 ↩︎
- San Antonio data centers guzzled 463 million gallons of water as area faced drought , July 2025 ↩︎
- The Debate On Data Center Development: Costs, Benefits, and Community Responses, ACE, April 2026 ↩︎
- Deriving Community Economic Development through Distributed Solar, Department of Energy, November 2024 ↩︎
- H.R.6984 - Data Center Transparency Act, Rep. Robert Menendez ↩︎
- Data Center Water and Energy Transparency Act, March 2026 ↩︎
- Louisville Community Data Center Cooperative Feasibility Study, Network Theory Applied Research Institute, November 2025 ↩︎
